BS

Implementing a Character-Level Markov Chain From Scratch
Sometime back, I watched a Veritasium video on Markov chains, and it pulled me into the whole lore around them. I learned that n-gram Markov models were actually used for text generation before LLMs, and at first, that felt similar to how LLMs work. Of course, that comparison does not really hold. Still, the idea felt simple enough to build, so I set out to implement a first-order, character-level Markov chain, also called a 1-character Markov chain.
First order markov chain
The main idea of a first-order Markov chain is that each character is dependent only on the previous character and nothing else. This is a modeling choice. Higher-order Markov chains can depend on more than one previous character.
In short, we'd go through a large text, then map each character to the upcoming characters and their frequencies.
For example, if we take 'hello', then the data structure would be:
{
'h': { 'e': 1 },
'e': { 'l': 1 },
'l': { 'l': 1, 'o': 1 },
'o': { '\n': 1 }
}
Now based on the above structure, we can say that 'e' follows 'h' 100% of the time, 'l' follows 'e' 100% of the time, 'l' or 'o' follows 'l' 50% of the time, etc.
Character states and transitions (first-order)
[h] → [e] → [l]
↘
[o] → [\n]
Each arrow represents a possible next character.
The number of times an arrow appears in the data determines its probability.
The dataset I've chosen is the works of Shakespeare.
Implementation
I built it in JavaScript. The core data structure is CharBucket, and it stores the character transitions.
The CharBucket implementation looks like this:
export default class CharBucket {
#storage = {};
insert(current, next) {
if (this.#storage[current] === undefined) {
this.#storage[current] = { [next]: 1 };
return true;
}
if (this.#storage[current][next] === undefined) {
this.#storage[current][next] = 1;
} else {
this.#storage[current][next] = this.#storage[current][next] + 1;
}
}
}
Now let us go on to read some Shakespeare.
Text ingestion pipeline
Text file
↓
Line-by-line stream
↓
Characters in each line
↓
(current character → next character)
↓
Frequency map (CharBucket)
This is the code that reads the file line by line and builds the frequency map:
async #processLineByLine() {
const fileReadStream = createReadStream(this.#FILE);
const readline = createInterface(fileReadStream);
readline.on("line", this.#processLine());
await once(readline, "close");
const jsonData = JSON.stringify(this.charBucket.getData(), null, 2);
await writeFile("data/shakespeare.json", jsonData, "utf-8");
}
#processLine() {
return (line) => {
line.split("").forEach((char, i) => {
if (this.charBucket.isEmpty()) {
this.charBucket.insert("START", char);
}
// Treat newline as just another character that connects lines together
if (!this.charBucket.isEmpty() && i === 0) {
this.charBucket.insert("\n", char);
}
if (i + 1 >= line.length) {
this.charBucket.insert(char, "\n");
return;
}
this.charBucket.insert(char, line[i + 1]);
});
};
}
This basically reads from the file and then saves it to a .json file for easy access next time. Notice how we add a special token 'START' as the very first character of the corpus.
Beginning of the corpus
START → T → h → e → ␠ → p → l → a → y → \n
↓
next line continues
Now moving on to generating some text. Once you have the frequency map, how do you generate text?
Generating text
One mistake I made when implementing this was to get all the possible next characters and then pick a random one out of the top K ones. The issue with this is that 'n' could appear after a character 100 times and 'z' one time, and we would end up assigning equal probability to each. This destroys the information that is stored in the frequency mapping.
Based on this example, the correct approach would be to pick 'n' 100/101 times and pick 'z' 1/101 times. This preserves the empirical distribution learned from the data. That is exactly what I've implemented.
The weighted sampling logic looks like this:
#findNextChar(current) {
const hashOfCurrent = this.charBucket.get(current);
if (hashOfCurrent === null) return null;
const entries = Object.entries(hashOfCurrent);
const total = this.#getTotal(entries);
const randomNumber = this.#getRandomInt(0, total);
let running = 0;
for (let i = 0; i < entries.length; i++) {
const [char, frequency] = entries[i];
running += frequency;
if (randomNumber < running) {
return char;
}
}
}
If the code looks confusing, visualize it this way. We create a line with 101 points. Then we place 'n' in 100 of them and 'z' in one of them. Now we generate a random number between 0 and 101, and based on that we select the character from the line. This makes sure that 'n' is picked 100/101 times and 'z' is picked 1/101 times.
Weighted selection visualization
Indexes: 0 100 101
|-----------------------------------|---|
Slots: n n n n n n n n n n ... (100 total) z
Random number selects a slot.
More slots = higher probability.
Now putting this all together, let's run the simulation:
async run(step = 100) {
let current = 'START';
for (let i = 0; i < step; i++) {
current = this.#findNextChar(current);
await this.#sleep();
await Bun.write(Bun.stdout, current);
}
}
We set the first character to 'START' and then start generating characters based on it. I've added a sleep there to mimic how LLMs respond.
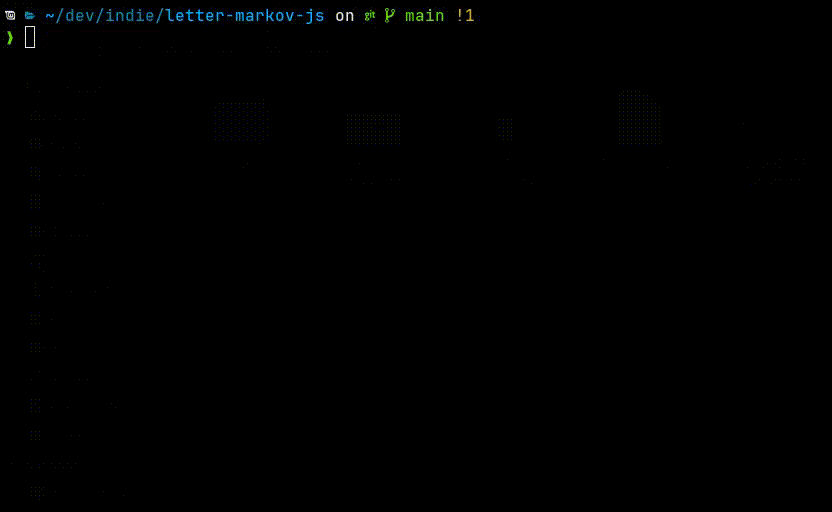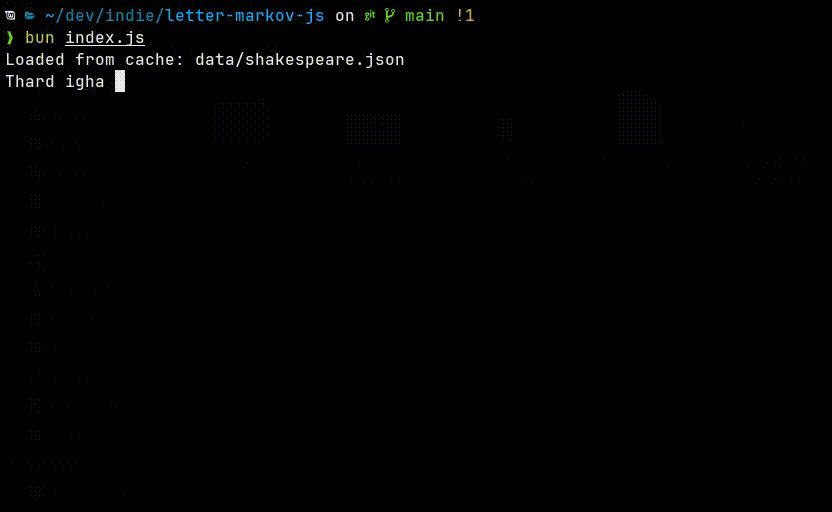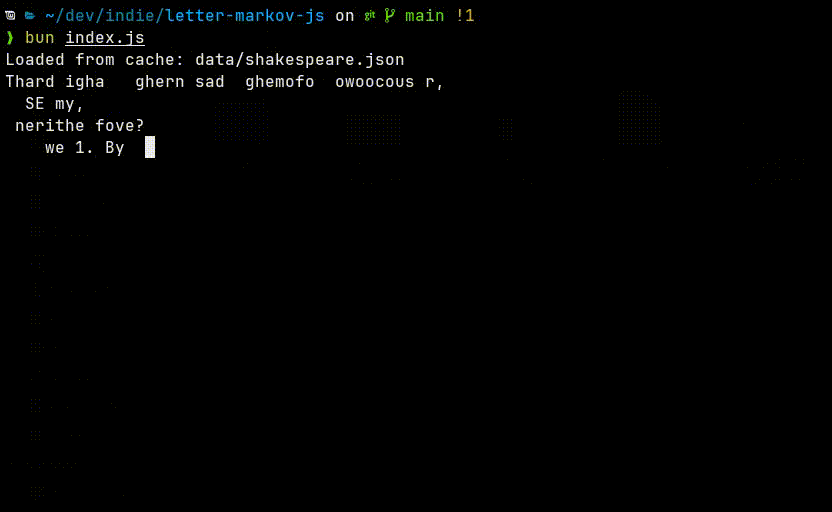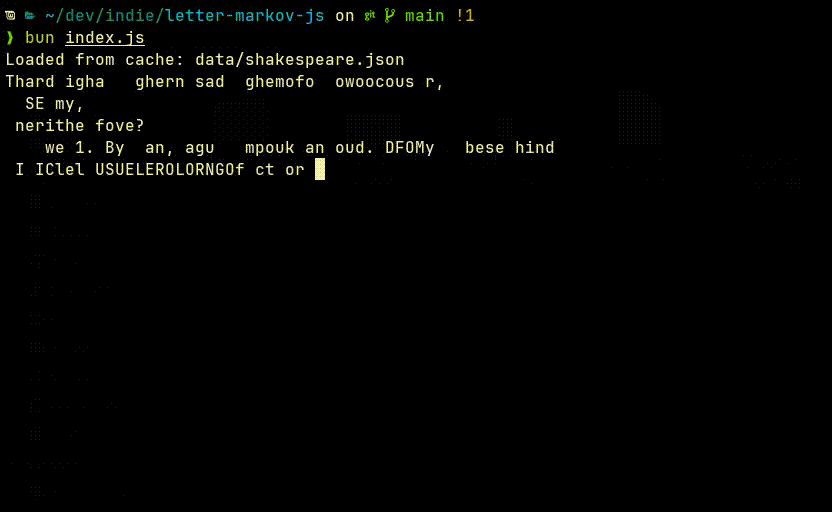
The output looks like nonsense, and that is expected. With only a single character of context, the model has almost no ability to maintain structure or meaning. But every now and then it creates some accurate words.
You can find the code at my github.
The next move would be to create a multiple-character Markov chain. In this example, the next character depends only on the previous character, but we can change that so that the next character depends on the previous N characters.
Conclusion
In the case of LLMs, the next token depends on all the tokens in the context, shaped by attention.
Before neural networks took over, n-gram models, essentially Markov chains with more context, were the state of the art for text generation. In that sense, there is a clear lineage from what I built here to modern language models, even though the mechanisms are fundamentally different.
My Markov chain looks at a single character, counts frequencies, and blindly follows surface patterns. An LLM looks at thousands of tokens, uses learned representations, and reasons over meaning and context. The scale and capability are worlds apart.
But the underlying idea is the same: given what came before, predict what comes next.
I built this out of curiosity, and to tinker with my brain. This was simple enough that I didn't need much help. I just needed to understand how it works and then write code. My wrong take on using a rank-based selection took me some time to figure out, but ChatGPT helped me out after being blocked for some time.